Understanding Confidence Intervals In R: A Guide For Data Analysis
Confidence intervals in R provide a range of values with a specific confidence level within which the true population parameter is likely to lie. To calculate, specify the sample mean, standard deviation, desired confidence level, and the appropriate distribution (normal or t-distribution). Use the R function t.test() with conf.level to specify the confidence level. Interpret the confidence interval by stating that with the given confidence level, the true population parameter falls within the calculated range. Advantages include quantifying uncertainty, while limitations include reliance on sample data and assumptions about the population distribution. Confidence intervals are valuable in decision-making in healthcare, finance, and research.
- Explain the purpose of confidence intervals.
- Describe the benefits of using confidence intervals in data analysis.
Unlocking the Mystery of Confidence Intervals
In the realm of data analysis, uncertainty lurks around every corner. How accurate are our measurements? Can we generalize our findings to a larger population? These are questions that keep data scientists awake at night.
Enter confidence intervals, the trusty statistical tool that helps us quantify uncertainty and make informed decisions. Imagine you’re conducting a survey to estimate the average height of adults in your city. The result is the sample mean, but there’s a chance it differs from the true population mean.
Confidence intervals give us a range of values within which we’re confident the true population mean lies. It’s like placing a guardrail around our estimate, giving us a buffer zone of uncertainty.
Benefits of using confidence intervals:
- Quantifying uncertainty: They acknowledge that our data is imperfect and provide a measure of its reliability.
- Making inferences: By comparing the confidence interval to a known value, we can determine if the population mean is significantly different.
- Supporting data-driven decisions: Confidence intervals help us assess the likelihood of different outcomes and make informed choices.
Understanding confidence intervals:
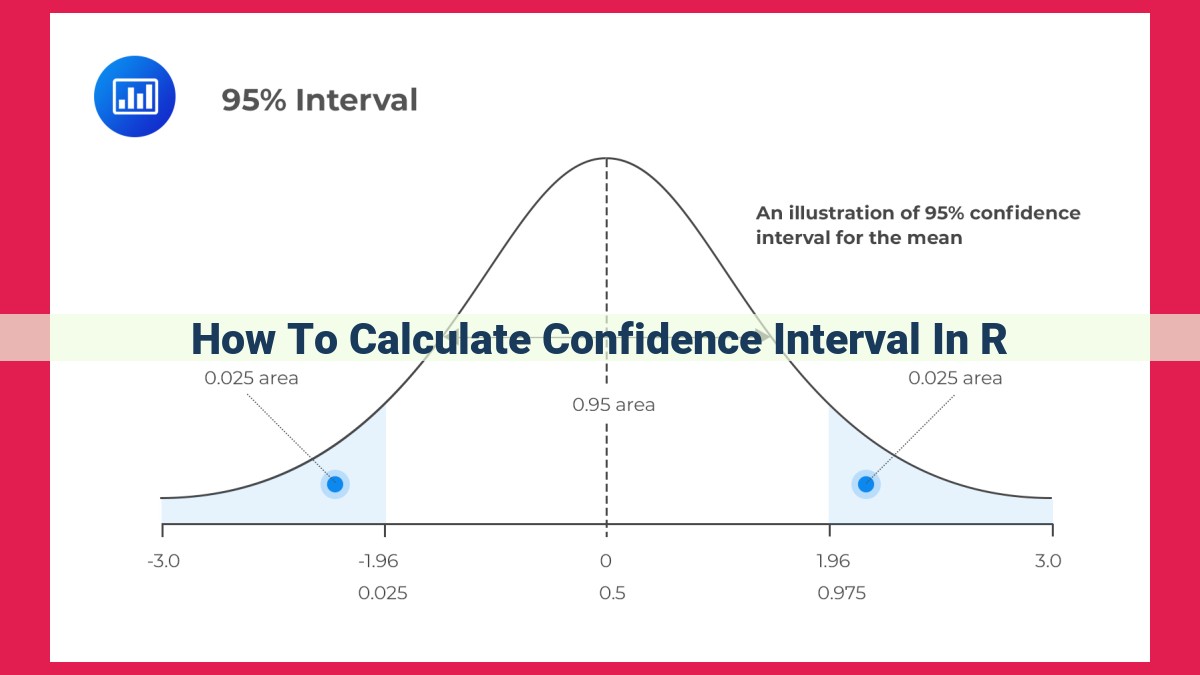
- Confidence level: The probability that the true population mean falls within the confidence interval (usually set at 95%).
- Margin of error: The distance between the sample mean and the end points of the confidence interval.
- Relationship: A higher confidence level means a wider margin of error.
Understanding Confidence Intervals: Unlocking the Power of Data Uncertainty
In the realm of data analysis, confidence intervals emerge as essential tools for navigating the inherent uncertainty that accompanies our observations. They provide a quantifiable framework for expressing the range of plausible values for an unknown population parameter, such as the true mean.
At its core, a confidence interval comprises two components:
-
Confidence Level: This value, often expressed as a percentage (e.g., 95%), represents the probability that the true population parameter falls within the interval. In other words, if we repeatedly draw samples from the population and calculate confidence intervals for each, the true value will lie inside the interval approximately 95% of the time.
-
Margin of Error: The width of the confidence interval, measured on either side of the sample estimate, reflects the precision of the estimate. A wider margin of error indicates less precision, while a narrower margin of error suggests greater precision.
The fascinating relationship between confidence level and width is inversely proportional. As the confidence level increases, the margin of error widens, and vice versa. This interplay stems from the fact that a higher level of confidence demands a broader range of plausible values to ensure the desired probability of capturing the true parameter.
Key Concepts for Confidence Interval Calculation
Sample Mean and Sample Standard Deviation
The sample mean is the average of a set of data points. It provides a central tendency of the data. The sample standard deviation measures the variation or spread of the data points around the sample mean. These two values are essential for calculating confidence intervals.
Margin of Error
The margin of error is a key component of confidence intervals. It represents the amount of uncertainty associated with the estimate. The larger the margin of error, the less precise the estimate. Conversely, a smaller margin of error indicates higher precision.
Z-score and t-score
The Z-score is a measure of how many standard deviations a given data point is from the mean. It assumes a normal distribution of the data. The t-score is similar to the Z-score but is used when the sample size is small or the population standard deviation is unknown. Both Z-score and t-score play a crucial role in calculating the critical value used to determine the confidence interval.
Calculating Confidence Intervals in R
In the realm of data analysis, understanding the uncertainty surrounding our estimates is critical. Confidence intervals offer a powerful tool to quantify this uncertainty and enhance our insights. In this section, we’ll dive into the practical aspects of calculating confidence intervals in the versatile programming language R.
To calculate a confidence interval, we start by understanding the sample mean and sample standard deviation. These statistics summarize the central tendency and spread of our data. The margin of error, which is a key component of the confidence interval, represents the maximum amount that our estimate could be off from the true population parameter.
The choice of distribution for calculating confidence intervals depends on the sample size and the shape of the distribution. For large sample sizes (typically n >= 30), we can use the normal distribution. For smaller sample sizes, the t-distribution, which takes into account the uncertainty in estimating the population standard deviation, is more appropriate.
To calculate a confidence interval in R, we can use the confint() function. This function takes the sample mean, sample standard deviation, sample size, and confidence level as arguments. The confint() function returns the lower and upper bounds of the confidence interval, along with the confidence level.
# Calculate the confidence interval for a sample mean
sample_mean <- 50
sample_sd <- 10
sample_size <- 100
confidence_level <- 0.95
confint(sample_mean, sample_sd, sample_size, confidence_level)
The output will display the lower and upper bounds of the confidence interval. By interpreting these bounds, we can make inferences about the population parameter with a certain level of confidence.
Example:
Suppose we have a sample of 100 students and the sample mean score is 75. If we want to construct a 95% confidence interval for the true population mean score, we can calculate the following:
sample_mean <- 75
sample_sd <- 12
sample_size <- 100
confidence_level <- 0.95
ci <- confint(sample_mean, sample_sd, sample_size, confidence_level)
The output will show that the 95% confidence interval for the true population mean score is (70.45, 79.55). This indicates that we are 95% confident that the true population mean score lies between 70.45 and 79.55.
Interpreting Confidence Intervals: Unlocking Meaning from Uncertainty
Understanding Confidence Intervals
Confidence intervals are not just statistical tools; they’re gateways to understanding the uncertainty inherently present in data. They provide a range of plausible values for unknown population parameters, helping us make informed decisions amidst the inevitable variability of the world.
Making Inferences with Confidence
When we construct a confidence interval, we’re essentially saying that with a certain level of confidence (typically 95%), the true population parameter lies within that range. This gives us a basis for inferring about the population from our sample.
Implications of Width
The width of a confidence interval is a key factor to consider in its interpretation. Wider intervals indicate greater uncertainty about the population parameter, while narrower intervals suggest greater precision. A narrow interval implies that our sample size is large enough to provide a reliable estimate of the population mean.
Real-World Applications
In the realm of healthcare, confidence intervals are used to gauge the effectiveness of treatments and estimate the risk of side effects. In finance, they help investors assess risk and return of investments. Researchers rely on confidence intervals to make inferences from survey data and draw conclusions about population characteristics.
By understanding and interpreting confidence intervals, we can navigate the world of uncertainty with increased clarity. They empower us to make better use of our data and draw meaningful conclusions, ensuring that our decisions are informed and our inferences are well-founded.
**Advantages and Limitations of Confidence Intervals**
Advantages of Confidence Intervals:
Confidence intervals provide several key advantages for data analysis:
-
Quantifying uncertainty: Confidence intervals allow us to estimate the range of possible values within which a population parameter (e.g., mean, proportion) may lie. This information is critical for decision-making, as it helps us understand the margins of error involved in our conclusions.
-
Precision estimation: By specifying a confidence level, we can control the precision of our estimates. A higher confidence level results in a narrower confidence interval, indicating a smaller range of possible values. This is particularly useful when we want to make precise inferences about the population.
Limitations of Confidence Intervals:
While confidence intervals are a powerful tool, they also have certain limitations:
-
Reliance on sample data: Confidence intervals are estimates based on sample data. The accuracy of these estimates depends on the representativeness and quality of the sample. A non-representative sample can lead to biased confidence intervals.
-
Assumptions about population distribution: Confidence interval calculations often rely on assumptions about the underlying population distribution (e.g., normal distribution). If these assumptions are not met, the confidence intervals may not be reliable.
-
Margin of error: Confidence intervals always have a margin of error, which represents the amount of uncertainty around the estimate. The margin of error can impact the practical significance of the results and should be carefully considered in decision-making.
Practical Applications of Confidence Intervals
Confidence intervals, powerful statistical tools, extend beyond theoretical concepts into a myriad of practical applications that shape our decision-making. Let’s explore their invaluable role in various fields:
Healthcare:
In clinical trials, confidence intervals provide a quantitative measure of treatment effectiveness. Researchers can confidently infer whether a new drug is significantly more efficacious than an existing one, guiding clinical practice.
Finance:
Financial analysts use confidence intervals to estimate the risk of an investment. By quantifying the uncertainty around stock prices, they help investors make informed decisions.
Research:
Researchers rely on confidence intervals to assess the accuracy of surveys and polls. By determining the margin of error, they can ensure that their findings reliably represent the target population.
Other Practical Applications:
Beyond these primary fields, confidence intervals pervade a wide range of practical scenarios:
- Marketing: Testing the effectiveness of advertising campaigns
- Manufacturing: Determining the quality of products
- Sports: Analyzing player performance over time
- Environmental science: Assessing the impact of human activities on ecosystems
In each of these cases, confidence intervals provide a solid foundation for data-driven decision-making, helping us to make informed choices based on reliable evidence.
