Unveiling The Precision Of Dna Replication: Semi-Conservative Replication For Genetic Accuracy
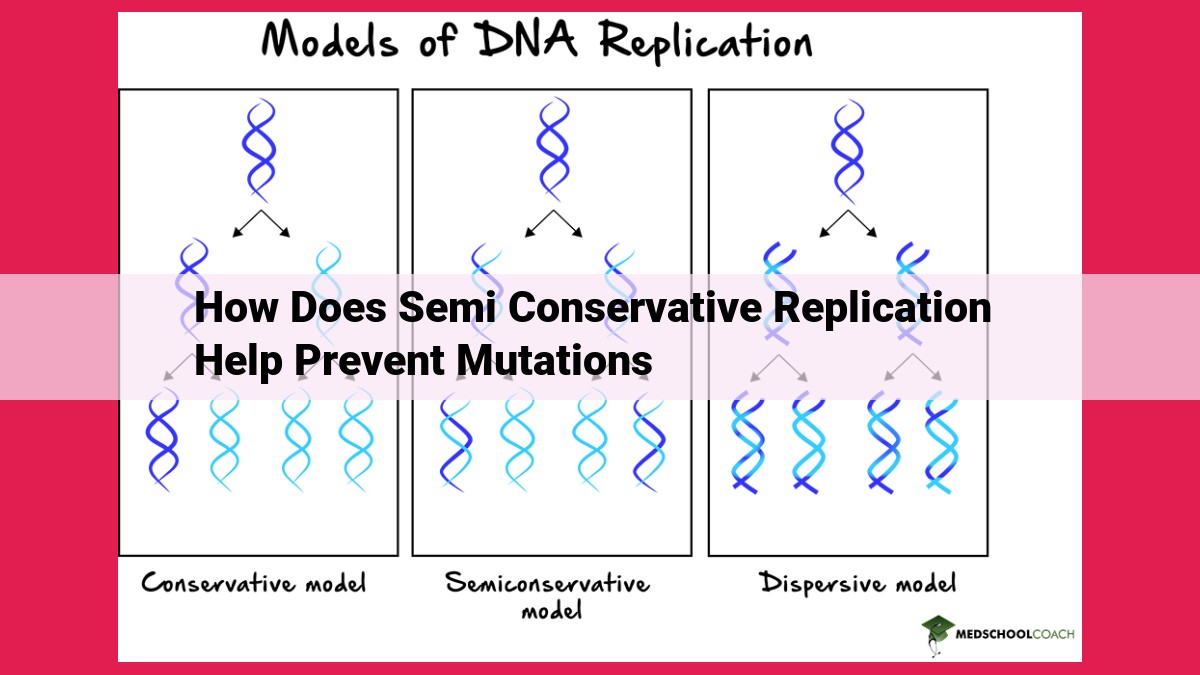
Semi-conservative replication preserves genetic accuracy by creating daughter DNA molecules with one original and one new strand, ensuring that each base pair is replicated only once. Complementary base pairing between A-T and G-C ensures accurate pairing during replication. DNA polymerases possess proofreading capabilities to correct errors, while repair mechanisms detect and correct any mismatches or damage to the replicated DNA. This ensures the fidelity of genetic information, preventing mutations and preserving genome stability, crucial for maintaining normal cellular function and preventing genetic diseases.
Genetic Fidelity: The Imperative of Accurate DNA Replication
In the realm of living organisms, DNA serves as the blueprint for life, carrying the genetic instructions that define each individual’s traits. The preservation of this precious genetic information is paramount, as even the slightest alteration can have profound consequences.
To ensure the fidelity of genetic information, nature has devised a remarkable mechanism known as semi-conservative replication. This process allows DNA to duplicate itself with exquisite accuracy, passing on genetic heritage from one generation to the next without compromising its integrity.
The Mechanics of Semi-Conservative Replication: Unraveling the Secret of Genetic Precision
In the realm of biology, the faithful transmission of genetic information is paramount for the continuity of life. Semi-conservative replication, a meticulously orchestrated process, ensures that this precious information is passed down through generations with remarkable accuracy.
At the heart of semi-conservative replication lies the origin of replication, the designated starting point from which DNA unzips like a double helix. As it unwinds, DNA polymerases, the molecular architects of DNA synthesis, meticulously add complementary nucleotides to each exposed strand. These newly synthesized strands, complementary to their existing counterparts, pair up with them in a dance of perfect harmony.
The process is not without its challenges, however. Introducing new nucleotides occasionally results in errors. But fear not! Nature has equipped us with proofreading mechanisms. DNA polymerases themselves possess exonuclease activity, allowing them to scrutinize their handiwork and remove any mismatched nucleotides. This meticulous attention to detail ensures that the newly synthesized strands are free from flaws.
Finally, once the new strands are complete, they are sealed together by the tireless efforts of DNA ligase. This enzyme acts like a master seamstress, stitching the fragments together to create a continuous, cohesive molecule.
Through this intricate choreography of unwinding, synthesizing, and sealing, semi-conservative replication ensures that each daughter molecule inherits one original strand and one newly synthesized strand, preserving the integrity of our genetic code.
Complementary Base Pairing: The Cornerstone of Genetic Accuracy
In the intricate tapestry of life, DNA plays a pivotal role as the blueprint of our genetic inheritance. Its unwavering accuracy is paramount to preserve the integrity of life’s blueprint. This article delves into the heart of this precision, exploring the crucial mechanism of complementary base pairing that underpins genetic fidelity.
The Art of Pairing: A Tale of Four Bases
Imagine DNA as a double helix, akin to a twisted ladder. The rungs of this ladder are made up of pairs of nucleotides, the building blocks of DNA. Each nucleotide consists of a sugar, a phosphate, and one of four nitrogenous bases: adenine (A), thymine (T), guanine (G), and cytosine (C).
The key to DNA’s precision lies in the complementary base pairing of these four bases. Adenine always pairs with thymine, and guanine always pairs with cytosine. This pairing is like a carefully crafted lock and key mechanism, ensuring the correct alignment and replication of genetic information.
The Watson-Crick Model: A Landmark Discovery
The discovery of complementary base pairing is attributed to the brilliance of James Watson and Francis Crick. Their groundbreaking 1953 model revealed the double helix structure of DNA and its intricate base-pairing rules. This model became the foundation for understanding how genetic information is stored and transmitted with remarkable accuracy.
Chargaff’s Rules: A Guiding Principle
Further solidifying the concept of complementary base pairing are Chargaff’s rules. These observations made by Erwin Chargaff in the 1940s showed that certain pairings of bases occur with predictable ratios in DNA. The amount of adenine in a DNA sample always equals the amount of thymine, and the amount of guanine equals the amount of cytosine. These ratios provide a compelling confirmation of complementary base pairing.
The Power of Complementary Base Pairing
The precision of complementary base pairing is essential for maintaining the integrity of genetic information. During DNA replication, each new strand of DNA is synthesized based on the sequence of the existing strand. The specific pairing rules between bases ensure that the newly synthesized strand is a precise copy of the original.
Moreover, complementary base pairing allows cells to recognize and repair any errors that may occur during DNA replication or by exposure to environmental hazards. The precise pairing of bases makes it possible for specialized enzymes to detect and correct these errors, preserving the accuracy of the genetic code.
Complementary base pairing is the cornerstone of genetic fidelity, ensuring the accurate transmission of genetic information from one generation to the next. The precise pairing rules between adenine and thymine, and guanine and cytosine, lay the foundation for the remarkable stability and accuracy of DNA, the blueprint of life. Without this fundamental principle, the inheritance of genetic traits and the very essence of life as we know it would be impossible.
Proofreading Mechanisms: Detecting and Correcting Errors in DNA Replication
In the intricate dance of DNA replication, accuracy is paramount. Mistakes in copying the genetic blueprint can lead to mutations, which can disrupt gene function and contribute to diseases. To safeguard against such errors, cells have evolved ingenious proofreading mechanisms that tirelessly scan and correct newly synthesized DNA.
The Exonuclease Shield: DNA Polymerase’s Secret Weapon
DNA polymerases, the molecular workhorses that synthesize new DNA strands, possess an extraordinary superpower: the ability to proofread their own work. Each polymerase molecule has a built-in exonuclease activity, an enzyme that can chew back the last nucleotide added if it doesn’t match the template correctly. Like a meticulous editor, the exonuclease ensures that only accurate base pairs are incorporated into the growing DNA strand.
RNA Priming: A Guiding Light for DNA Synthesis
The initiation of DNA synthesis at specific sites on the template strand is critical for accurate replication. Enter RNA primers, short stretches of RNA synthesized by a specialized enzyme called primase. RNA primers provide a foothold for DNA polymerase to begin adding nucleotides and extending the new DNA strand. Once the DNA strand has reached a certain length, the RNA primer is removed and replaced by DNA, ensuring a precise and continuous replication process.
The precision of semi-conservative replication, the protective shield of proofreading mechanisms, and the precision of RNA priming work in harmony to preserve genetic fidelity, safeguarding the integrity of our genetic inheritance. These mechanisms ensure that the DNA blueprints passed down from generation to generation remain as pristine as possible, protecting us from the perils of genetic disorders and ensuring the continuity of life.
Repair Mechanisms: Shielding the Genetic Fortress from Peril
In the labyrinth of life, DNA serves as the blueprint for our existence. Preserving its integrity is paramount, for any imperfections can disrupt the symphony of cellular processes. To safeguard this precious code, cells employ an arsenal of repair mechanisms, ready to mend the wounds inflicted by environmental hazards or the relentless passage of time.
Base Excision Repair: Snipping Out Damaged Bases
Imagine DNA as a string of beads, each bead representing a nucleotide base. When a base is damaged, it resembles a faulty bead that could disrupt the entire strand. Base excision repair steps in as the diligent bead remover, snipping out the damaged base with surgical precision. Specialized enzymes called DNA glycosylases do the honors, scanning the DNA for any misfits. Once a damaged base is detected, the glycosylase snips it away, leaving a gap in the strand.
Nucleotide Excision Repair: Removing Bulky Lesions
Sometimes, the damage to DNA is more extensive, requiring a more comprehensive repair approach. Enter nucleotide excision repair. It’s like a molecular SWAT team, targeting bulky lesions that distort the DNA’s shape. A team of proteins scans the DNA, identifying the damaged segment. They then alert a specialized enzyme, UV endonuclease, which cuts out the damaged region, leaving a larger gap in the strand.
Mismatch Repair: Correcting Mistakes After Replication
After DNA replication, errors can arise during the hasty copying process. Mismatch repair acts as the vigilant proofreader, scrutinizing the newly synthesized strand for any mismatches between the old and new sequences. It’s like a grammar checker for DNA, detecting and correcting any deviations from the original text. A team of proteins compares the old and new strands, identifying and replacing any mismatched bases with the correct ones.
These repair mechanisms are the unsung heroes of our cells, tirelessly protecting the integrity of our genetic code. Without them, mutations would accumulate, potentially leading to genetic disorders, diseases, and even cancer. By ensuring the fidelity of our DNA, these repair systems play a critical role in safeguarding the foundation of our very existence.
