5 Essential Outlier Detection Methods In R: A Comprehensive Guide For Data Analysts
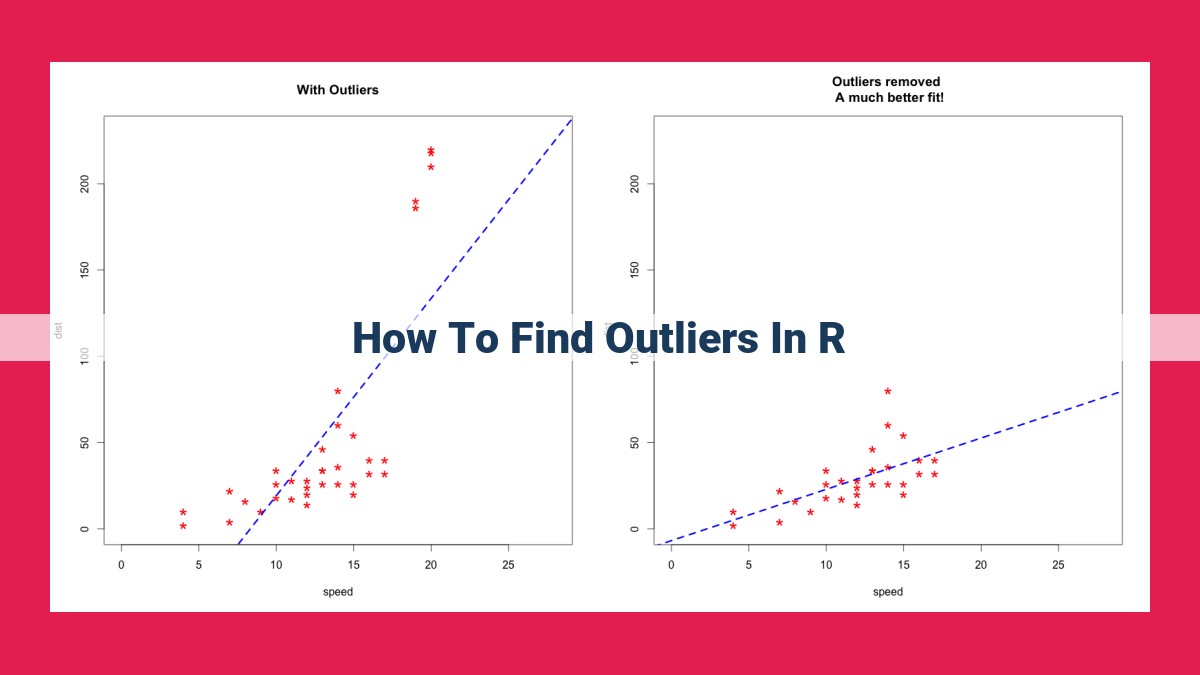
Outliers, extreme data points, can significantly impact data analysis. Detecting outliers in R involves several methods: IQR identifies outliers based on the interquartile range; Grubbs’ Test uses a hypothesis test to define statistical significance; Dixon’s Q Test employs a non-parametric approach; Mahalanobis Distance identifies multivariate outliers; and Cook’s Distance measures influence in regression models. Each method has advantages and limitations, and choosing the appropriate approach depends on data characteristics. Understanding the underlying concepts and limitations of each method is crucial for accurate outlier detection and reliable data analysis.
Outliers: Detecting and Understanding Data Anomalies
Data is the cornerstone of modern decision-making, but not all data is created equal. Outliers, Extreme values that deviate significantly from the norm, can lurk within datasets and potentially skew analysis results. Identifying and handling outliers is crucial to ensure accurate and reliable data interpretations.
In this blog post, we’ll delve into the world of outlier detection, exploring various methods to identify and understand these data anomalies. From the simple yet effective IQR method to the more sophisticated Mahalanobis distance, we’ll shed light on their advantages, limitations, and applications.
Why Outlier Detection Matters
Outliers can arise from measurement errors, data entry mistakes, or simply natural variations. Ignoring them can lead to erroneous conclusions and biased insights. Detecting outliers helps us:
- Improve data quality: Removing outliers can enhance the overall accuracy and reliability of our data.
- Identify anomalies: Pinpointing outliers can reveal inconsistencies, fraudulent activities, or other underlying issues.
- Enhance analysis results: By excluding outliers, we can obtain more accurate estimates, better model fitting, and more robust statistical inferences.
Outlier Detection: The IQR Method
In the vast expanse of data, outliers stand out like beacons, holding the potential to skew analysis and lead to inaccurate conclusions. Detecting these anomalies is crucial for ensuring the integrity and reliability of your data. Among the many outlier detection methods, the Interquartile Range (IQR) method stands out for its simplicity and effectiveness.
Understanding IQR
IQR is a measure of variability that represents the range of the middle 50% of data points. It is calculated as the difference between the upper quartile (Q3) and the lower quartile (Q1).
Outlier Identification Using IQR
Tukey’s method, a widely used IQR-based approach, defines outliers as data points that fall beyond 1.5 * IQR below Q1 or above Q3. These extreme values can significantly distort the overall distribution and should be carefully examined.
IQR Method in Practice
To identify outliers using IQR, follow these steps:
- Sort your data from smallest to largest.
- Calculate Q1 as the median of the lower half of the data.
- Calculate Q3 as the median of the upper half of the data.
- Calculate IQR as Q3 – Q1.
- Identify outliers as data points that are less than Q1 – 1.5 * IQR or greater than Q3 + 1.5 * IQR.
Advantages of IQR Method
- Easy to understand and implement.
- Robust to extreme values.
- Suitable for detecting outliers in both symmetric and skewed distributions.
Limitations of IQR Method
- Can be sensitive to sample size.
- May not be suitable for detecting multiple outliers.
- Assumes the data follows a normal distribution.
By understanding the concept of IQR and Tukey’s method, you can effectively detect outliers in your data and ensure the accuracy and reliability of your analysis.
Grubbs’ Test: Unmasking Outliers with Statistical Hypothesis Testing
In the realm of data analysis, outliers can be a perplexing encounter. They are data points that deviate significantly from the rest, potentially skewing results and undermining the integrity of your findings. To combat this challenge, Grubbs’ test emerges as a powerful statistical hypothesis test designed to identify these enigmatic data points.
Unveiling Grubbs’ Test
Grubbs’ test is rooted in the assumption that your data follows a normal distribution. It operates on the premise that if an outlier exists within your dataset, it would perturb the mean of the data. Thus, Grubbs’ test sets out to determine whether the suspected outlier is sufficiently distant from the mean to warrant its exclusion from the analysis.
Mechanics of Grubbs’ Test
To execute Grubbs’ test, you must first calculate the Grubbs’ statistic (G), which measures the deviation of the suspected outlier from the mean relative to the standard deviation of the data. Mathematically, G is expressed as:
G = |X - μ| / s
where:
- X is the suspected outlier
- μ is the mean of the data
- s is the standard deviation of the data
Once you have calculated G, you can determine the p-value associated with the statistic. The p-value represents the probability of obtaining a value of G as extreme or more extreme than the one you observed, assuming the suspected outlier is not an outlier.
Significance Calculation
The p-value plays a crucial role in the decision-making process. If the p-value is less than your chosen significance level (α), it indicates that the suspected outlier is statistically significant and cannot be attributed to random chance. In this case, you would reject the null hypothesis that there is no outlier and conclude that the data point is an outlier. Conversely, if the p-value is greater than α, you would fail to reject the null hypothesis and retain the outlier in your dataset.
By leveraging Grubbs’ test, you can confidently detect outliers in your data, ensuring that your analysis is not compromised by extreme data points. Remember, the choice of significance level (α) is a delicate balance between the risk of false positives (incorrectly identifying an outlier) and false negatives (failing to identify a true outlier).
Dixon’s Q Test: Unveil Outliers with Non-Parametric Precision
Identifying outliers is crucial for data analysis. They can distort results, leading to erroneous conclusions. Among the various outlier detection methods, Dixon’s Q test stands out for its non-parametric nature. Unlike parametric tests, it makes no assumptions about the distribution of the data, making it versatile for analyzing diverse datasets.
Calculating the Q Statistic
The Q statistic is the cornerstone of Dixon’s Q test. It measures the discrepancy between a suspected outlier and the remaining data points. The formula for the Q statistic is:
Q = (X_max - X_min) / (X_(n-1) - X_1)
where:
- X_max is the largest data value
- X_min is the smallest data value
- X_(n-1) is the second largest data value
- X_1 is the second smallest data value
Interpreting the Q Statistic
The Q statistic is compared to a critical value, which depends on the sample size. If the Q statistic exceeds the critical value, it indicates the presence of a significant outlier. The critical values can be found in tables or calculated using statistical software.
Advantages and Disadvantages
Dixon’s Q test has several advantages:
- Non-parametric: It does not require assumptions about data distribution.
- Robust: It is insensitive to extreme values.
- Simple: It is easy to calculate and interpret.
However, it also has limitations:
- Lacks power: It may not detect outliers if they are close to other data points.
- Sensitive to sample size: The critical values change with sample size, affecting the sensitivity of the test.
Choosing Dixon’s Q Test
Dixon’s Q test is appropriate when:
- The data is non-normally distributed.
- There are only a few suspected outliers.
- The sample size is small to moderate.
Dixon’s Q test is a valuable tool for detecting outliers in non-parametric datasets. By understanding the concept of the Q statistic and its interpretation, data analysts can effectively identify and handle outliers, ensuring the accuracy and reliability of their analysis.
Mahalanobis Distance: Unveiling Multivariate Outliers
In the realm of data analysis, outliers often lurk, camouflaged among the multitude of observations. These anomalous data points can skew results, leading to biased conclusions and misguided decision-making. To safeguard against this, data analysts employ a repertoire of techniques, including the venerable Mahalanobis distance.
Multivariate Outliers and Mahalanobis Distance
Traditional outlier detection methods, such as the IQR method, struggle to identify outliers in multivariate datasets, where multiple variables are involved. This is where Mahalanobis distance steps in. It extends the concept of distance to multidimensional space, capturing the deviation of a data point from the multivariate mean while accounting for correlations between variables.
Calculating Mahalanobis Distance
The Mahalanobis distance (MD) for an observation x is calculated as follows:
MD = √[(x - μ)ᵀ Σ⁻¹ (x - μ)]
where:
* μ is the multivariate mean
* Σ is the covariance matrix
* Σ⁻¹ is the inverse of the covariance matrix
The covariance matrix describes the relationships between the variables, allowing MD to consider how the variables interact with each other.
Interpreting Mahalanobis Distance
The MD quantifies the distance between an observation and the multivariate mean in terms of standard deviations. A smaller MD indicates closer proximity to the mean, while a larger MD suggests greater deviation. By comparing the MD of each observation to a critical value, analysts can identify potential outliers.
Advantages and Limitations of Mahalanobis Distance
- Strength: Captures the complex relationships between variables in multivariate datasets.
- Limitation: Requires the assumption of a multivariate normal distribution, which may not always hold true.
Mahalanobis distance is a powerful tool for detecting multivariate outliers, providing a more comprehensive analysis of complex datasets. By understanding the concept and limitations of this technique, data analysts can make informed choices in their outlier detection strategies, ensuring the accuracy and reliability of their data analyses.
Cook’s Distance
- Introduce Cook’s distance as a measure of influence
- Describe how Cook’s distance can identify outliers in regression models
Cook’s Distance: Uncovering Hidden Outliers in Regression Models
In the world of data analysis, outliers are often pesky intruders that can wreak havoc on our models. They’re like mischievous little gremlins, lurking in the shadows and waiting to distort our results. But fear not, for we have a secret weapon in our arsenal: Cook’s distance.
Cook’s distance is a clever measure of influence that can help us identify outliers in regression models. It’s a way of quantifying how much a single data point affects the overall model fit. In other words, it tells us which points are pulling our model too far in one direction or another.
To calculate Cook’s distance, we compare the model’s predictions with and without a given data point. If the difference is large, then that data point is an outlier with potentially influential effects. It’s like removing a weight from one end of a seesaw and seeing how much the other side rises.
Cook’s Distance in Action
Let’s imagine we have a regression model that predicts house prices based on factors like square footage and number of bedrooms. If one of the data points has an unusually low price compared to its size and number of bedrooms, that point might have a high Cook’s distance.
Why are we interested in high Cook’s distances? Because outliers can skew our model’s predictions. If we build a model based on the entire dataset, including the outlier, our predictions might be off for other houses that don’t have such extreme values. By understanding the influence of individual data points, we can make more accurate predictions and avoid being misled by anomalies.
Choosing Your Method
Like all good tools, Cook’s distance has its strengths and weaknesses. It’s particularly useful for identifying outliers in linear regression models. However, it’s not as effective for nonlinear models or datasets with high correlations.
If you’re unsure which outlier detection method to use, consider the characteristics of your data. For example, if your data is normally distributed, the IQR method might be a good choice. If you have a small sample size, Grubbs’ Test might be more suitable. And if you’re dealing with multivariate outliers, Mahalanobis distance is a valuable tool.
By understanding the different outlier detection methods and their limitations, you can make informed decisions about which one to use for your data analysis. With these tools in your toolbox, you’ll be able to uncover hidden outliers, improve the accuracy of your models, and make more informed decisions.
Comparing Outlier Detection Methods: Unraveling the Best Fit for Your Data
In the realm of data analysis, outliers stand out as anomalies that can significantly skew results and lead to flawed conclusions. Identifying and handling these outliers is crucial for accurate and reliable data analysis. To aid in this endeavor, a plethora of outlier detection methods exists, each with its unique advantages and limitations.
IQR Method: Simplicity and Robustness
The IQR method relies on the concept of the interquartile range (IQR) to identify outliers. It is a non-parametric method, meaning it makes no assumptions about the underlying distribution of the data. IQR identifies outliers as data points that fall below Q1 – 1.5IQR or above Q3 + 1.5IQR, where Q1 and Q3 are the first and third quartiles, respectively. This method is simple to implement and robust to outliers, making it a good choice for large datasets or data with extreme values.
Grubbs’ Test: Statistical Rigor for Small Datasets
Grubbs’ test is a statistical hypothesis test that assumes the data follows a normal distribution. It evaluates the significance of the difference between the suspected outlier and the rest of the data. If the calculated significance value is less than a predefined threshold, the data point is considered an outlier. Grubbs’ test is particularly useful for small datasets, typically containing fewer than 100 data points.
Dixon’s Q Test: Non-Parametric Flexibility
Like the IQR method, Dixon’s Q test is a non-parametric method. It calculates the Q statistic, which represents the ratio of the range of the data with and without the suspected outlier. A large Q statistic indicates a potential outlier. Dixon’s Q test is suitable for identifying outliers in small to medium-sized datasets, regardless of the underlying distribution.
Mahalanobis Distance: Multivariate Outlier Detection
Mahalanobis distance is a measure of how far a data point is from the center of a multivariate distribution. It considers the correlations between variables, making it effective in detecting outliers in high-dimensional datasets. Data points with a large Mahalanobis distance are considered potential outliers.
Cook’s Distance: Influential Outliers in Regression Models
Cook’s distance measures the influence of a data point on the fitted regression line. A high Cook’s distance indicates that the data point has a disproportionate effect on the model. While not strictly an outlier detection method, Cook’s distance can help identify data points that may require further investigation, especially in regression analysis.
Method Selection: Tailoring to Data Characteristics
Choosing the appropriate outlier detection method depends on the nature of the data and the specific analysis goals. For large datasets or data with extreme values, the IQR method is a robust option. Grubbs’ test is suitable for small datasets that follow a normal distribution. Dixon’s Q test is a non-parametric alternative for datasets of varying sizes and distributions. Mahalanobis distance is ideal for detecting outliers in multivariate datasets. Cook’s distance is useful for identifying influential outliers in regression models.
Outlier detection is an essential step in data analysis, helping to ensure the accuracy and reliability of results. By understanding the concepts and limitations of different outlier detection methods, analysts can choose the most appropriate method for their specific data characteristics. This approach empowers data-driven decision-making and leads to more informed and valuable insights.
